
by Haixun Wang, Vice President of Engineering and Head of AI at EvenUp
The lifeblood of many businesses is still locked away in documents: PDFs, images, tables, charts, handwritten notes, screenshots, and more.
In personal injury law, a single firm might manage a mountain of cases. Each case stretches across hundreds or even thousands of pages collected over years. The answers that matter most—who did what, when, where, for how much, and backed by what evidence—aren’t neatly organized. Instead, they’re scattered across a chaotic landscape of formats and files, waiting to be discovered and connected.
That’s why Document AI, which uses LLMs and generative AI to transform unstructured documents into structured, actionable data, is becoming foundational infrastructure across legal, healthcare, insurance, finance, and the public sector. EvenUp's work in legal tech is just one example of a larger movement: how to turn unstructured artifacts into durable knowledge, then automation, then decisions people can trust.
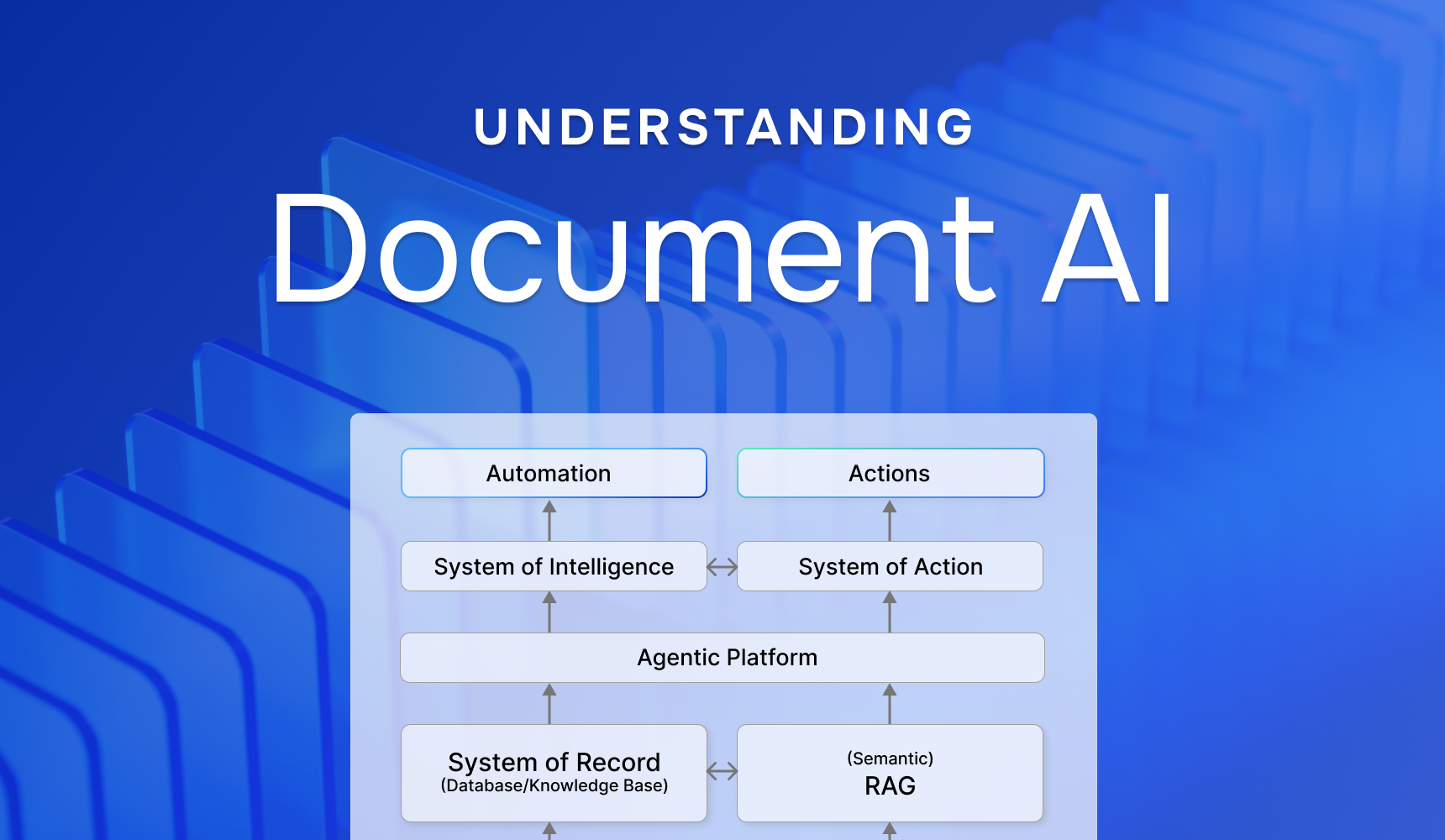
We view Document AI as a progression of capabilities, each building on the last to deliver increasing value:
First, transform unstructured documents into structured, persistent knowledge with clear provenance. Without this reliable memory layer, nothing else can scale or be trusted.
With a solid memory in place, the next step is automation. Drafting a demand letter draws directly from known facts, supplemented by retrieval for citations and relevant case knowledge. Human review remains available, but the default is efficient, autonomous operation.
Finally, enable timely, informed decisions. With a memory spanning cases, the system can proactively recommend actions—contacting providers, nudging stakeholders, or requesting missing records—at the right moment.
________________
In this post, we focus on the importance and challenges of building a System of Record as the foundational step. In future posts, we’ll share our approaches to developing this layer and discuss how we extend these principles to the System of Intelligence and System of Action.
Most first-generation Document AI systems follow a simple pipeline: PDF → OCR → chunked retrieval (RAG) → LLM, as illustrated in Figure 1. While this approach can produce impressive demos quickly, it soon encounters significant, inherent limitations:

RAG has its merits, but without a persistent, structured memory layer, every query is a cold start. This makes it difficult to link information across documents, leads to valuable knowledge being lost, and prevents corrections from accumulating over time—ultimately undermining the reliability of the system.
If a basic LLM wrapper isn’t enough, where do we begin? There are many challenges in building robust Document AI, but let’s start with the foundation: PDF extraction. This isn’t just a preliminary hurdle—it’s a microcosm of the entire problem space. Every complexity we’ll face downstream, such as unstructured layouts, ambiguous data, mixed modalities, and the need for reliable provenance, shows up right here in the first step.

Figure 2 exemplifies some of the challenges we are dealing with. It leads to a stack of research problems: layout analysis, table structure recovery, checkbox state detection, handwriting OCR, diagram understanding, and image semantics. In legal and healthcare, small marks matter—an initialed checkbox can invert a meaning; a handwritten note can override a printed field; a diagram can carry causality the text never states.
Let’s dive into a concrete challenge: Figure 3 is a visual included in the above police report that depicts a multi-vehicle accident. This image communicates crucial details about the incident—often much more than the brief accompanying text in the police report, which cannot answer many of the questions that the visual evidence makes clear.

Modern multimodal LLMs are capable of interpreting images and answering related questions. However, if we depend on a vision-language model (VLM) to analyze the accident image every time a question is asked, we encounter more than just increased cost and latency. The fundamental problem is that the system never develops a persistent, internal understanding of the accident. Instead of extracting and storing structured information from the image, we are forced to repeatedly re-process the raw image for each query. This means our pipeline from PDF to structured data remains incomplete, preventing us from building a lasting, reusable representation of the visual evidence.
Here is our preferred approach:
How can we make sure the summary captures all the details needed to answer future questions? One effective strategy is to use reinforcement learning based on answerability: we train the system so that its summaries enable accurate answers to likely downstream queries. Figure 4 illustrates this process.

More specifically, our goal is to convert an image (like an accident diagram) into a compact textual summary that lets downstream systems answer the same questions they could have answered from the pixels—without calling a vision model every time. We “grade” a summary by its answerability: if a text-only QA model can recover the right answers from the summary, the summary is good; if not, it must improve.
We start by manufacturing supervision directly from the image. A vision-language model looks at the diagram and generates a diverse set of questions that reflect what users actually ask—who and how many, where things are, what happened and in what order, who likely failed to yield, and what parts of the image are uncertain. The same model then answers those questions from the pixels, giving us a grounded Q/A set that acts like temporary “truth” for training.
Next, a summarizer model—the one we aim to train—turns the image into a short, schema-conformant description. For example, instead of freeform prose, it writes in predictable sections, which include entities (vehicles, signs, lanes), layout (positions and relative distances), ordered events (merge, impact, debris), causality cues (e.g., likely failure to yield, with confidence), and explicit uncertainty.
To evaluate the summary, we hide the image and ask a text-only QA model to answer the original question set using nothing but the summary. This cleanly tests whether the summary preserved the facts that matter.
We then calculate the reward. The core is agreement between text-only answers and pixel-grounded answers. On top, we add bonuses for internal consistency, and penalties for verbosity or breaking the output schema. A KL regularizer keeps the summarizer’s language stable and readable rather than drifting into odd styles just to game the reward.
We train the summarizer using Proximal Policy Optimization (PPO), a reinforcement learning method designed for stable and efficient policy updates. PPO works by sampling model outputs, measuring their performance, and then adjusting the model’s parameters to improve future results, while explicitly constraining each update so the model doesn’t change too abruptly. This balance allows the summarizer to steadily improve while maintaining reliability and avoiding instability during training.
At deployment, each image gets summarized once at ingestion. We store the summary in the System of Record with full provenance (page/image IDs, bounding regions, model versions, timestamps) and link its entities to case entities so it joins cleanly with text-extracted facts. Most future queries that hinge on visual evidence run at text speed against this summary; if confidence is low or a new question type appears, we can fall back to a pixel check for that specific case and, if needed, update the stored summary.
A simple RAG can surface something quickly, but it leaves too much to chance when evidence is scattered across lengthy, multimodal documents. Fortunately, both industry and academia are actively developing ways to make RAG more robust: structure-aware indexing that can parse tables and forms, multi-hop retrieval that tracks entities and timelines, citation-verified generation, calibration and uncertainty estimation, and agentic workflows that decompose complex questions into smaller, checkable steps. All of these innovations share a common goal: producing answers that are well-supported, consistent, and auditable.
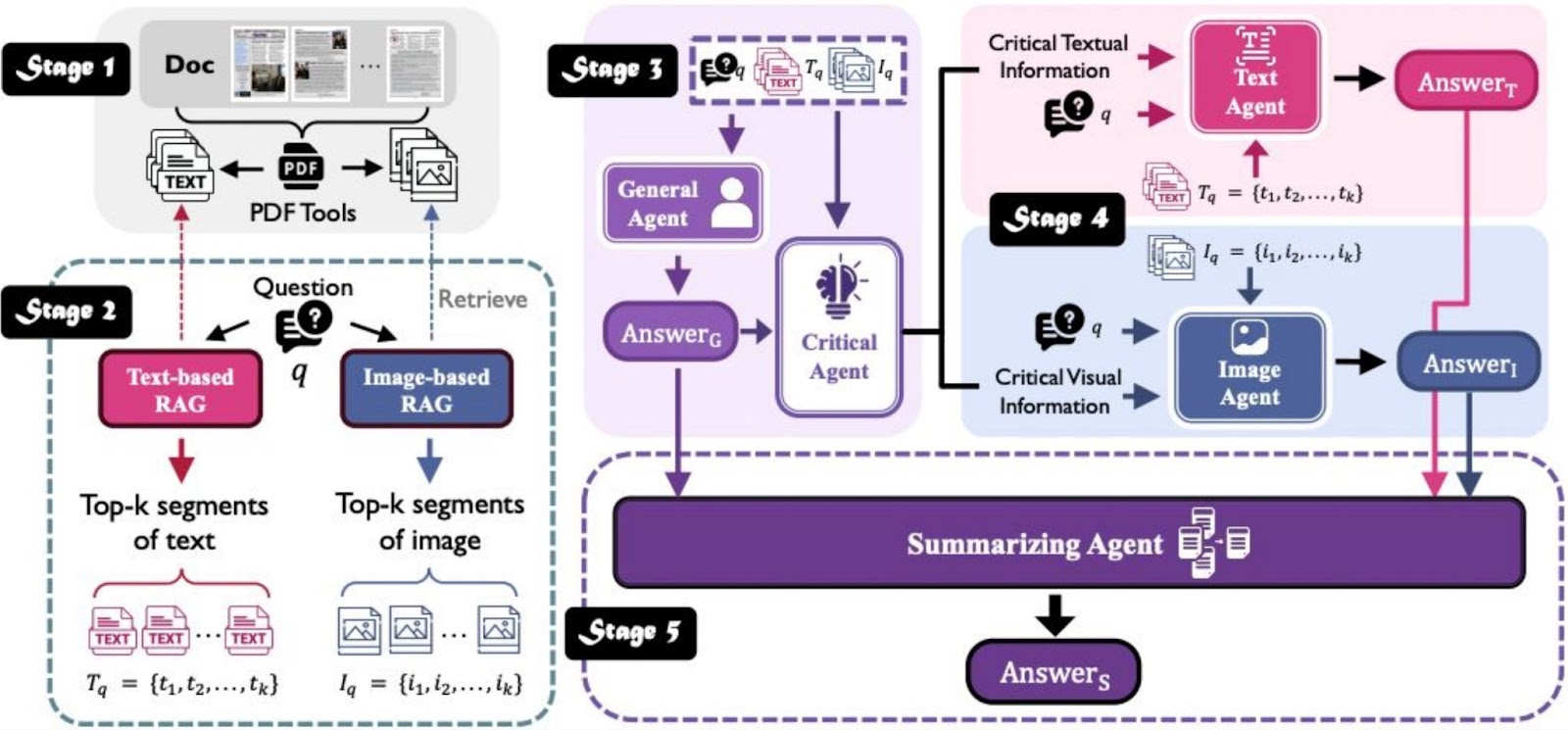
As one concrete example on the reliability front, consider work like MDocAgent. It begins as many systems do, retrieving chunks (including images) and drafting an answer. Then, agent-critics directly question the RAG itself, asking reviewer-style queries such as: Why is this true? Where is the evidence? What page or figure supports that claim? The RAG responds to these agent-generated challenges with targeted follow-up retrievals. New passages and visual snippets are gathered, and a summarizer or adjudicator agent weaves them into a rationale that either confirms or revises the original answer. The result is fewer unsupported claims and answers that consistently show their evidence.
This kind of agentic, evidence-seeking loop is just one lane in a much wider highway of RAG improvements. In practice, the strongest systems compose several of these ideas: they retrieve more intelligently, reason in smaller verified steps, and attach the proof. In our own platform, we fold those reliability gains back into the broader arc—System of Record → System of Intelligence → System of Action—so that what’s verified once doesn’t vanish after the page closes.
Up to now, our approach has been to answer each question in a top-down manner. In personal-injury cases, documents can stretch across thousands of pages, and even straightforward queries, like “total billed by Provider X” or “how many visits to Clinic Y,” require searching through countless chunks scattered throughout the case file. The system aggregates on the fly, every time, which is slow, costly, and error-prone. This is the gap: there is no place where facts become durable, queryable, and auditable. The missing layer is a System of Record.

The architecture we advocate begins by building that record from the bottom up, then layering intelligence and action on top. The figure in the deck captures it; here is the storyline behind it.
Start at ingestion, but don’t stop at text. We normalize what comes in: PDFs, scans, handwriting, tables, and images. Visuals are converted into compact, faithful descriptions once, using the reinforcement-learning approach described earlier, then linked to page regions and stored alongside text with shared provenance. From these sources we construct case entities (claimant, providers, encounters, procedures, line items, vehicles or scenes), the relationships between them, and timelines. Every field carries source links and model versions. When a human corrects a value, that correction becomes part of the record, with lineage.
Let questions plan against memory, not pages. With the record in place, the system plans mixed executions. Parts of a question that are factual execute directly on the record; parts that require tone or rationale use retrieval over the underlying documents. Explanations cite both: the rows in the record and the exact spans or image regions that justified them. A request like “how many visits did the plaintiff make to Clinic Y” becomes a stable lookup rather than a thousand-page reading assignment, while “explain the sequence of events in the collision” pulls the structured scene summary and the diagram snippets that support it.
Actions become natural, and they leave trails. Once facts live in a record, gaps and next steps are visible. Missing records can be requested from the right provider; drafts of outreach and demand letters assembled from the record’s facts and cited quotes; stakeholders can be nudged at the right moment based on timelines and confidence. Each action is logged with inputs, outputs, and approvals. When uncertainty is high or a constraint fails, the system asks for help and remembers the answer, which improves future plans.
This is the core flow: System of Record → System of Intelligence → System of Action. The record anchors reliability; the intelligence layer plans how to combine queries, retrieval, and generation; the action layer executes safely and keeps an audit.
There is a practical benefit that clarifies why this matters. In the top-down world, every aggregate is recomputed from raw pages and is hard to verify. In the record-first world, the same questions become simple and auditable. You can think of them as SQL rather than improvisation, and the provenance graph shows exactly where each figure came from and which document spans support it. That is how trust accumulates.
We also care deeply about how the record is built at scale. Three goals guide our design: First, accuracy—fields must be correct, reconciled, and traceable to their sources. Second, cost—the system should extract information once and reuse it, rather than repeatedly invoking large models for every query; our image-to-text reinforcement learning approach is one lever here. Third, coverage—not just isolated fields, but the entire case across entities, events, relationships, and timelines, all captured efficiently in a small number of passes.
In upcoming blog posts, we’ll dive deeper into each of these components: how we construct the record at scale, evolve schema and entity linking without breaking history, perform temporal reasoning across long horizons, and build an evaluation and calibration harness that mirrors real-world operations. Stay tuned for detailed explorations of these building blocks.
Document AI is crossing a threshold—from clever wrappers to durable systems that remember, automate, and act with care. The research community is pushing multimodal reasoning, agentic evidence, and RL-based summarization. The industry is translating those ideas into platforms that can stand up to governance, latency, and cost. The prize is huge: an operating system that turns unstructured reality into operational memory—and then into outcomes people can trust.
We’re building along these lines and will share deeper dives on our System of Record patterns, evaluation and calibration loops, and multimodal training strategies (including “summarize once, reuse forever”). If this resonates, follow along—Document AI is a big tent, and the next breakthroughs will come from people who care both about ideas and about making them work in the world.
________________
Haixun Wang is VP of Engineering and Head of AI at EvenUp. Haixun leads the development of generative AI for the legal sector—advancing document understanding, document generation, and building systems of intelligence and action that transform how legal work is done. He is an ACM Fellow, IEEE Fellow, Editor-in-Chief of the IEEE Data Engineering Bulletin, a trustee of VLDB, and an Affiliate Professor at the University of Washington. Previously, Dr. Wang held senior leadership roles in AI, applied science, NLP, and knowledge bases at Instacart, WeWork, Amazon, and Meta, and earlier conducted research at Microsoft, Google, and IBM. He has authored more than 200 publications in top journals and conferences, with work recognized through multiple prestigious awards, including the ICDE 10-Year Influential Paper Award (2024), the ICDE Best Paper Award (2015), the ICDM 10-Year Best Paper Award (2013), and the ER Best Paper Award (2009).
.png)
